Introduction to Diffusion Models

Source: NVIDIA. Link to Page
Diffusion models are a type of generative model that simulates the natural data generation process. They are characterized by a forward process that adds random noise to the input sample and a reverse process that iteratively denoises noisy samples to generate high-quality samples that closely approximate its training data distribution.

Source: NVIDIA. Link to Page
Diffusion networks such as DALL-E, Midjourney, and most recently SORA by OpenAI, have found success in the domain of images, videos and audios where data is inherently continuous. However, the application of diffusion models in natural language has been limited because text is inherently discrete in nature. Despite that, recent research has successfully applied continuous diffusion on text and shown breakthrough in conditional text generation. The success of diffusion models in conditional text generation can be attributed to the end-to-end learning of feature and embedding space of text.
Diffusion Models for Conditional Text Generation
Source: DiffuSeq. Link to Page
We follow the architecture of DiffuSeq (Gong et al. 2023) that performs partial noising on a text sequence. Given a source sequence (prompt) and a target sequence (response), DiffuSeq learns the feature and embedding spaces by partially corrupting the embedding space of a target sequence in the forward process. In the reverse process, the source sequence serves as guidance for denoising the noisy word embeddings to reconstruct the target sequence.
More details of the diffusion process are as follow:
- The input sequence is a combination of the source (x) and target (y) sequence separated by a separator token.
- In the forward process, random Gaussian noise is added to the target sequence’s embeddings iteratively at every timestep while keeping the source sequence unchanged.
- In the reverse process, a BERT-based transformer is used to predict the noise added to the combined sequence at any given timestep as the noisy sequence is being denoised gradually to recover the original sequence z.
Data
We use Shakespeare’s plays in our task to demonstrate that diffusion models are able to capture complex semantics and structures of text. We arrange conversations in the format: {src: <text>, trg:<text>}
Each sequence is capped at a length of 200 characters. Our train data consists of 32,531 data samples, each is a pair of source-target sequence while our validation data contains 8,123 data samples. Furthermore, we train a tokenizer on the original Shakespeare’s plays consisting of 30,268 vocabularies.
Extensive effort is taken to clean the dataset, such as:
- Removing non-conversational lines and non-English lines (mostly in Henry V)
- Segmenting conversations by the last punctuation within the specified length of sequence
- Grouping lines of conversations of each character based on their turns in each act scene.
Experiments
Some notable experiments that we have conducted include:
- Transfer Learning
- Modern dialogue & Shakespeare plays → Shakespeare plays
- Shakespeare plays → Comedies in Shakespeare plays only
- Data Engineering
- Conversation length
- With and without shuffling conversations
- More Shakespeare by adding Shakespeare’s sonnets
- Fine-tuning transformer
- Warm up steps
- Layer-wise learning rate decay (LLRD)
- Reinitializing the last layer of encoder
- Hyperparameters
- Diffusion steps, dropout rate, batch size, hidden dimension, and weight decay
The best-trained model emerged when LLRD and warm-up steps are introduced, strategies not originally present in the DiffuSeq model.
Our final best-trained model has 1000 diffusion steps, 128 hidden dimension, 0.1 dropout rate, 0.0 weight decay, batch size of 30 and layer-wise learning rate decay of 0.9 with a starting learning rate of 0.0001 at the bottom-most layer (closest to input). The model is trained on 1 GPU with 30,000 epochs and 500 warm up steps, taking roughly 7-8 hours. The effect of reinitializing the last layer of the encoder transformer is negligible.
Results
Our models are able to sample new continuations of Shakespeare lines that match a similar sentiment to the Shakeaspearean line input into the model. Our models perform better when trained on long input sequences. Our model samples are also of high diversity, with many different possible lines that follow the given line. These responses are not entirely coherent all the time however, as some generations may not follow the given line well, and thus some human verification may be required.
Table 1 shows some example responses that the diffusion model generated at each of the
following diffusion steps and the prompt that was used.
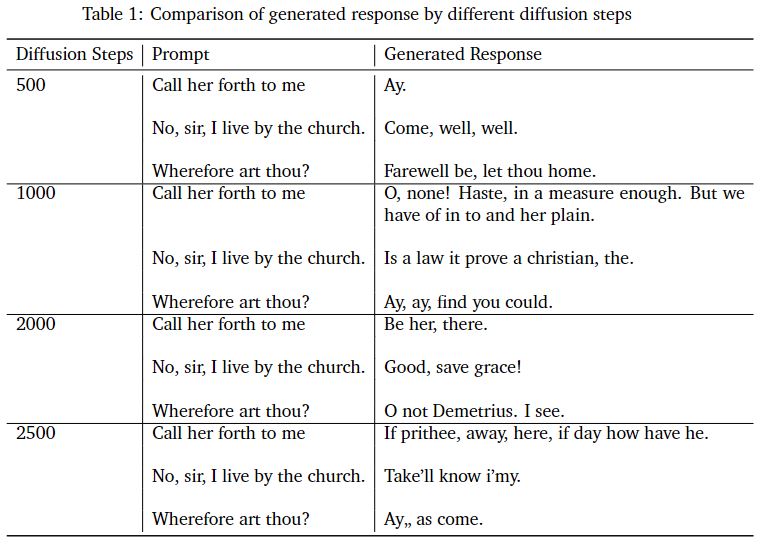
Figure 1 below visually depicts the embedding space of positive and negative words learned by our model and shows how the model can clearly cluster similar words belonging to comedies or tragedies.

Figure 1: UMAP projection of word embeddings by positive and negative sentiments
When the model is trained with character names at the start of each conversation in the source-target pairs, we find the our model is able to capture some level of social network amongst the characters. Figure 2 below visually depicts the embedding space of character names in selected plays and shows how our model can associate characters of the same play.
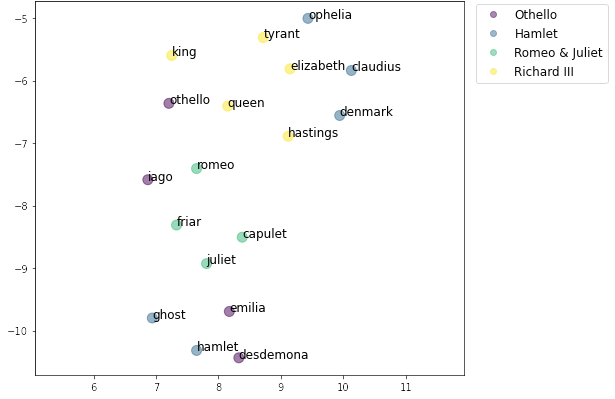
Figure 2: UMAP projection of character names in selected famous plays
Discussion & Conclusion
The experiments involved in training a text generation model based on Shakespearean plays and sonnets revealed several key findings. Initially attempting to train on a combination of plays and sonnets proved ineffective due to the distinct differences between conversational dialogue and poetic structures. Furthermore, despite multiple attempts at transfer learning, the model struggled to grasp modern text structures given our training setup before fine-tuning on Shakespearean data.
Cleaning the data was crucial for model performance, with the method of sentence segmentation and conversation length significantly impacting results. Particularly, limiting conversations to a maximum of two participants and cutting sentences based on the last line break within a sequence length of 200 characters proved beneficial.
Moreover, randomizing the data was deemed essential, as training on consecutive lines in any specific play led to poor performance due to the strong correlation between data samples within the same play.
We find that our modified DiffuSeq lacks at upholding sentence coherence. We hypothesize that this could be attributed to the end-to-end training of embedding space (i.e. using a pre-trained embedding model should result in better sentence coherence) and quality of training data used to train these models.
Last but not least, it is important to take into account the many different hyperparameters that can be adjusted, and to also consider the tradeoffs that these hyperparameters pose. Diffusion steps is an important hyperparameter, as it gives the model an easier prediction task with a larger amount of timesteps at the cost of slower sampling and the possibility of overfitting due to the smaller noise required to be predicted between each timestep.
Meet the Team Behind

Left to Right: Alexander Jensen, (Mentor) Arya Mazumdar, (Winfrey) Xian Ying Kong, Joseph Samuel
